全球热文:AI搜索大战已全面打响
 (相关资料图)
(相关资料图)
美国《大西洋月刊》7月30日文章,原题:人工智能搜索战已全面打响 每时每刻,世界各地的人们在搜索引擎上输入数以万计的词条,年搜索量达数万亿次。数十亿人在浏览互联网的搜索引擎网站。包括谷歌、微软和OpenAI在内的许多强大的科技公司,最近都发现了用生成式人工智能(AI)重塑这一领域的机会,它们正在竞相抓住这个机会——AI搜索大战已然全面打响。
AI搜索栏的价值显而易见:与其打开和阅读多个链接,不如把问题输入聊天机器人的页面,然后立即得到答案,这样岂不是更好?不过,为了让这种方法奏效,AI模型必须能够从网上抓取相关信息。ChatGPT问世近两年后,用户日益意识到许多AI产品实际上建立在窃取信息的基础上,科技公司正试图与提供这些内容的媒体出版商建立关系。现在,AI可能会先“咀嚼和反刍”,然后根据其不透明的底层算法决定用户看到的内容。这也意味着,目前媒体机构向许多用户展示广告和销售订阅,但用户访问媒体出版商网站的理由将会减少。
AI模型除了训练数据之外没有抓取最新信息,这些数据往往是几个月或几年之前的。今年6月,当我第一次与AI搜索公司Perplexity首席商务官谢韦连科交谈时,他表示:“我们长期成功的关键因素之一,是媒体出版商不断创作事实充足的新闻,因为如果没有准确的原始材料,AI就无法很好回答。”
AI公司似乎并不把人类的文字、照片和视频视为艺术品或劳动产品;相反,它们将内容视为信息的采掘矿藏。“人们来Perplexity不是为了消费新闻,是为了消费事实。”谢韦连科告诉我。Perplexity和记者并不直接竞争——前者回答问题,后者是发布突发新闻或提供意见和想法。但谢韦连科承认,AI搜索给媒体网站带来的流量将少于传统搜索引擎,因为用户点击链接的理由更少——机器人正在直接提供答案。因此,越来越多的AI与媒体之间的交易是一种勒索。
但媒体至少也有一定的能力来限制AI搜索引擎读取其网站的能力——拒绝签署或重新谈判协议,甚至起诉AI公司侵犯其版权,正如《纽约时报》所做的。AI公司似乎有自己的方法绕过媒体的障碍,但这是一场正在进行的军备竞赛,没有明显的赢家。OpenAI等公司能否赢得AI搜索大战,可能并不完全取决于它们的软件:媒体合作伙伴也是等式的重要组成部分。
AI搜索大战试图改变人们浏览互联网的方式,而互联网是当今世界组织和传播知识的一张超级大网。但底层地基并没有改变:知识,无论以何种形式存在,仍然是人类的经验、智慧和思考的结晶,而不是机器人的机械抓取。(作者马特奥·王,陈欣译)▲
- 全球热文:AI搜索大战已全面打响 美国《大西洋月刊》7月30日文章,原题:人工智能搜索战已全面打响每时
-
 罗山县举行漯河(国家级)知识产权快速维权中心罗山工作站揭牌仪式 7月24日上午,漯河(国家级)知识产权快速维权中心罗山工作站揭牌仪式
罗山县举行漯河(国家级)知识产权快速维权中心罗山工作站揭牌仪式 7月24日上午,漯河(国家级)知识产权快速维权中心罗山工作站揭牌仪式 -
 国家发改委:宏观经济治理体系不断健全,我国经济实力大幅提升 中新网8月1日电 1日,国新办举行推动高质量发展系列主题新闻发布会
国家发改委:宏观经济治理体系不断健全,我国经济实力大幅提升 中新网8月1日电 1日,国新办举行推动高质量发展系列主题新闻发布会 -
 多措并举破解科创企业融资难_每日速讯 《中共中央关于进一步全面深化改革、 推进中国式现代化的决定》提
多措并举破解科创企业融资难_每日速讯 《中共中央关于进一步全面深化改革、 推进中国式现代化的决定》提 -
 国家能源局:上半年全社会用电量约4.7万亿千瓦时 中新网7月31日电 7月31日,国家能源局举行新闻发布会,国家能源局
国家能源局:上半年全社会用电量约4.7万亿千瓦时 中新网7月31日电 7月31日,国家能源局举行新闻发布会,国家能源局 -
 通道业务再出新花样 监管敦促财险公司自查短期健康险 “团体补充医疗保险”伪创... “频繁惹事”的短期健康险业务,又一次迎来全面自查整改。近日,国家金
通道业务再出新花样 监管敦促财险公司自查短期健康险 “团体补充医疗保险”伪创... “频繁惹事”的短期健康险业务,又一次迎来全面自查整改。近日,国家金
- 全球热文:AI搜索大战已全面打响 美国《大西洋月刊》7月30日文章,原题:人工智能搜索战已全面打响每时
-
 再爆违规,丰田首次被责令整改 环球观天下 日本共同社1日报道称,关于汽车量产所需的“型式指定”认证违规问题,
再爆违规,丰田首次被责令整改 环球观天下 日本共同社1日报道称,关于汽车量产所需的“型式指定”认证违规问题, -
 再爆违规,丰田首次被责令整改|世界球精选 日本共同社1日报道称,关于汽车量产所需的“型式指定”认证违规问题,
再爆违规,丰田首次被责令整改|世界球精选 日本共同社1日报道称,关于汽车量产所需的“型式指定”认证违规问题, -
 我国消费品品种总量突破2亿种,位居全球第一|焦点关注 记者今天了解到,据市场监管总局所属中国物品编码中心统计,截至202
我国消费品品种总量突破2亿种,位居全球第一|焦点关注 记者今天了解到,据市场监管总局所属中国物品编码中心统计,截至202 -
 AI搜索大战已全面打响|世界快报 美国《大西洋月刊》7月30日文章,原题:人工智能搜索战已全面打响每时
AI搜索大战已全面打响|世界快报 美国《大西洋月刊》7月30日文章,原题:人工智能搜索战已全面打响每时 -
 造纸行业将进入旺季 部分纸品价格或发生分化|天天热讯 8月份,造纸行业开始逐步进入市场传统旺季。8月1日起,国内包装纸行业
造纸行业将进入旺季 部分纸品价格或发生分化|天天热讯 8月份,造纸行业开始逐步进入市场传统旺季。8月1日起,国内包装纸行业 -
 今日聚焦!上半年规上电子信息制造业增加值同比增13.3% 8月1日电(记者王政、刘温馨)记者从工业和信息化部获悉,今年以来,我国
今日聚焦!上半年规上电子信息制造业增加值同比增13.3% 8月1日电(记者王政、刘温馨)记者从工业和信息化部获悉,今年以来,我国 -
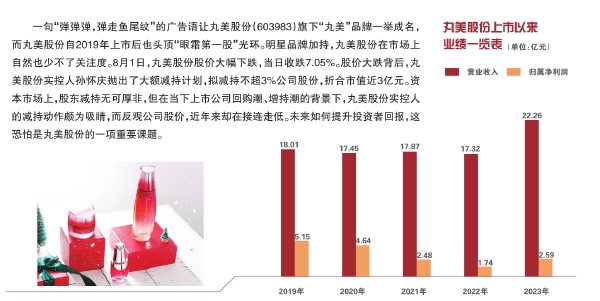 实控人拟减持重创股价 丸美股份不完美 一句弹弹弹,弹走鱼尾纹的广告语让丸美股份(603983)旗下丸美品牌
实控人拟减持重创股价 丸美股份不完美 一句弹弹弹,弹走鱼尾纹的广告语让丸美股份(603983)旗下丸美品牌 -
 磷酸铁锂电池6月份装车量占比达74% 近日,中国汽车动力电池产业创新联盟(以下简称“电池联盟”)发布最新数
磷酸铁锂电池6月份装车量占比达74% 近日,中国汽车动力电池产业创新联盟(以下简称“电池联盟”)发布最新数 -
 充电桩市场呈现高景气 相关上市公司业绩受益 8月1日晚间,道通科技披露2024年半年报。今年上半年,公司实现营业总收
充电桩市场呈现高景气 相关上市公司业绩受益 8月1日晚间,道通科技披露2024年半年报。今年上半年,公司实现营业总收 -
 新职业·新动能:从业三年 他眼中的智能网联汽车测试员“大有可为” 7月31日,人力资源社会保障部向社会发布了19个新职业,这些新职业半
新职业·新动能:从业三年 他眼中的智能网联汽车测试员“大有可为” 7月31日,人力资源社会保障部向社会发布了19个新职业,这些新职业半 -
 我国自研视频大模型面向全球上线|天天快播报 输入文字描述或上传图片,就能生成一段逼真视频。近日,我国自主研
我国自研视频大模型面向全球上线|天天快播报 输入文字描述或上传图片,就能生成一段逼真视频。近日,我国自主研 -
 充电桩市场呈现高景气 相关上市公司业绩受益 8月1日晚间,道通科技披露2024年半年报。今年上半年,公司实现营业总收
充电桩市场呈现高景气 相关上市公司业绩受益 8月1日晚间,道通科技披露2024年半年报。今年上半年,公司实现营业总收 -
 中国人工智能视频生成产品密集上线 今日热文 新华社北京8月1日电(记者张漫子)在对话框中输入一句话或添加一张
中国人工智能视频生成产品密集上线 今日热文 新华社北京8月1日电(记者张漫子)在对话框中输入一句话或添加一张 -
 观点:充电桩市场呈现高景气 相关上市公司业绩受益 8月1日晚间,道通科技披露2024年半年报。今年上半年,公司实现营业总收
观点:充电桩市场呈现高景气 相关上市公司业绩受益 8月1日晚间,道通科技披露2024年半年报。今年上半年,公司实现营业总收 - 全球热头条丨中国元素添彩奥运(奥运观澜) 在巴黎奥运会开幕前夕,1000多架中国企业制造的无人机升上巴黎夜空
-
 零跑汽车7月交付量创新高,创始人强调成本定价策略重要性 8月2日消息,零跑汽车公布了其7月的交付数据,共交付出22093辆,同比增
零跑汽车7月交付量创新高,创始人强调成本定价策略重要性 8月2日消息,零跑汽车公布了其7月的交付数据,共交付出22093辆,同比增 -
 环球热点!暑期热度攀升 哈尔滨机场单月客流量创同期历史新高 中新社哈尔滨8月2日电 (记者 史轶夫)哈尔滨机场8月2日发布消息,
环球热点!暑期热度攀升 哈尔滨机场单月客流量创同期历史新高 中新社哈尔滨8月2日电 (记者 史轶夫)哈尔滨机场8月2日发布消息, -
 网络主播成新职业 乐见“新职人”直播间里收获成功_热消息 7月31日,人社部网站公布了人社部等3部门联合发出的通知。通知公布
网络主播成新职业 乐见“新职人”直播间里收获成功_热消息 7月31日,人社部网站公布了人社部等3部门联合发出的通知。通知公布 -
 蔚来7月交付量环比微降,李斌称要看企业长期竞争力 全球热文 8月2日消息,日前蔚来汽车发布了2024年7月的交付数据。数据显示,蔚来
蔚来7月交付量环比微降,李斌称要看企业长期竞争力 全球热文 8月2日消息,日前蔚来汽车发布了2024年7月的交付数据。数据显示,蔚来 - 【天天时快讯】建设全国统一大市场 将从“破”“立”两方面发力 在8月1日国务院新闻办公室举行的推动高质量发展系列主题新闻发布会
-
 世界简讯:参股期货概念2日主力净流出12.88亿元,锦龙股份、东方财富居前 8月2日,参股期货概念下跌1 41%,今日主力资金流出12 88亿元,概念股4
世界简讯:参股期货概念2日主力净流出12.88亿元,锦龙股份、东方财富居前 8月2日,参股期货概念下跌1 41%,今日主力资金流出12 88亿元,概念股4 -
 日本推出新款人形机器人,无须环境信息即可运作 8月2日,据日媒报道,日本立命馆大学和滋贺县草津市的机器人创新企业“
日本推出新款人形机器人,无须环境信息即可运作 8月2日,据日媒报道,日本立命馆大学和滋贺县草津市的机器人创新企业“ -
 港股概念追踪 |黄金期货价格再创历史新高 机构金价展望2600美元(附概念股) 天天快资讯 COMEX黄金再度升破2500美元 盎司关口,涨幅0 8%。
港股概念追踪 |黄金期货价格再创历史新高 机构金价展望2600美元(附概念股) 天天快资讯 COMEX黄金再度升破2500美元 盎司关口,涨幅0 8%。 -
 参股期货概念2日主力净流出12.88亿元,锦龙股份、东方财富居前 8月2日,参股期货概念下跌1 41%,今日主力资金流出12 88亿元,概念股4
参股期货概念2日主力净流出12.88亿元,锦龙股份、东方财富居前 8月2日,参股期货概念下跌1 41%,今日主力资金流出12 88亿元,概念股4 -
 港股概念追踪 |黄金期货价格再创历史新高 机构金价展望2600美元(附概念股) COMEX黄金再度升破2500美元 盎司关口,涨幅0 8%。
港股概念追踪 |黄金期货价格再创历史新高 机构金价展望2600美元(附概念股) COMEX黄金再度升破2500美元 盎司关口,涨幅0 8%。 -
 10Y美债收益率跌破4%!美债领涨全球公债 30年期中国国债期货再刷历史新高_信息 美国国债收益率周四下跌,原因是投资者消化了美联储主席鲍威尔暗示9月
10Y美债收益率跌破4%!美债领涨全球公债 30年期中国国债期货再刷历史新高_信息 美国国债收益率周四下跌,原因是投资者消化了美联储主席鲍威尔暗示9月 - 发挥“慈善+金融”合力 南华期货探索善本金融新路径-全球新动态 8月1日,南华期货善本信托浙金-南华慈善信托正式启动。浙商银行党委书
-
 8月2日“农产品批发价格200指数”比昨天上升0.59个点-全球快看 中新网8月2日电 据农业农村部网站消息,据农业农村部监测,8月2日
8月2日“农产品批发价格200指数”比昨天上升0.59个点-全球快看 中新网8月2日电 据农业农村部网站消息,据农业农村部监测,8月2日 -
 海通证券:美国天然气期货价格持续下跌,光伏产业链价格维持低位_天天热议 海通证券发布研报称,美国天然气期货价格较前一周继续下跌,天然气库存
海通证券:美国天然气期货价格持续下跌,光伏产业链价格维持低位_天天热议 海通证券发布研报称,美国天然气期货价格较前一周继续下跌,天然气库存 -
 羊山新区二十里河街道“不卷课堂”“暑期青少年心理健康进社区行动”走进苏庙社区-... 为促进青少年的心理健康发展,提高他们应对生活和学习中各种挑战的能力
羊山新区二十里河街道“不卷课堂”“暑期青少年心理健康进社区行动”走进苏庙社区-... 为促进青少年的心理健康发展,提高他们应对生活和学习中各种挑战的能力 -
 息县:扎实推进河长制工作 切实筑牢汛期安全防线 为持续巩固澺河河道管护治理成效,不断提升河流水域环境治理水平,入汛
息县:扎实推进河长制工作 切实筑牢汛期安全防线 为持续巩固澺河河道管护治理成效,不断提升河流水域环境治理水平,入汛 -
 信阳市邮政分公司联合七里棚社区开展地质灾害应急避险演练 为深入践行“人民至上、生命至上”的理念,扎实做好地质灾害防治工作,
信阳市邮政分公司联合七里棚社区开展地质灾害应急避险演练 为深入践行“人民至上、生命至上”的理念,扎实做好地质灾害防治工作, -
 罗山县行政审批和政务信息管理局多举措做好安全生产管理工作 近年来,罗山县行政审批和政务信息管理局认真贯彻落实县委县政府各项安
罗山县行政审批和政务信息管理局多举措做好安全生产管理工作 近年来,罗山县行政审批和政务信息管理局认真贯彻落实县委县政府各项安 -
 标准普尔全球评级确认中国再保、中再产险、中再寿险、中再寿险(香港)、桥社爱尔... 近日,标准普尔全球评级正式确认中国再保及旗下中再产险、中再寿险、中
标准普尔全球评级确认中国再保、中再产险、中再寿险、中再寿险(香港)、桥社爱尔... 近日,标准普尔全球评级正式确认中国再保及旗下中再产险、中再寿险、中 - 中信保诚人寿着力打造新时代卓越保险企业家|速看 中信保诚人寿着力打造卓越保险企业家,开启高质量发展新篇章在利率
-
 罗山县:AI语音回访 助力企业满意度提升 为进一步提升企业满意度,罗山县行政审批和政务信息管理局持续推行人工
罗山县:AI语音回访 助力企业满意度提升 为进一步提升企业满意度,罗山县行政审批和政务信息管理局持续推行人工 -
 每日观察!内乡县赵店乡组织开展青少年心理健康教育讲座 为帮助青少年树立正确的心理健康观念,掌握有效的心理调适方法,促进他
每日观察!内乡县赵店乡组织开展青少年心理健康教育讲座 为帮助青少年树立正确的心理健康观念,掌握有效的心理调适方法,促进他 -
 郑州私立高中一览表2023|环球头条 郑州私立高中一览表2023
郑州私立高中一览表2023|环球头条 郑州私立高中一览表2023 -
 西峡法院:头顶烈日量曲直 现场勘验促公正 今日看点 7月31日,烈日当头,酷暑难耐,西峡法院法官对一起小区之间道路通行的
西峡法院:头顶烈日量曲直 现场勘验促公正 今日看点 7月31日,烈日当头,酷暑难耐,西峡法院法官对一起小区之间道路通行的 - 上证基金指数下跌1.13%,前十大权重包含500ETF等 8月2日消息,上证指数下跌0 92%,上证基金指数(基金指数,000011)下跌1
-
 驻马店驿城区老街街道:党建引领业委会换届 共绘社区治理“同心圆” 为进一步发挥党建引领红色业委会建设,维护业主的合法权益,营造整洁舒
驻马店驿城区老街街道:党建引领业委会换届 共绘社区治理“同心圆” 为进一步发挥党建引领红色业委会建设,维护业主的合法权益,营造整洁舒 -
 世界快看:潮涌大通道 开放新格局——西部陆海新通道加速跑 陆海内外联动、东西双向互济。西部陆海新通道,这条跨越山海的国际
世界快看:潮涌大通道 开放新格局——西部陆海新通道加速跑 陆海内外联动、东西双向互济。西部陆海新通道,这条跨越山海的国际 -
 世界最资讯丨文明服务 礼仪先行——罗山县“小满大讲堂”第14期开讲啦 为持续优化政务环境,做实做深“小满帮办”政务服务品牌,进一步提升政
世界最资讯丨文明服务 礼仪先行——罗山县“小满大讲堂”第14期开讲啦 为持续优化政务环境,做实做深“小满帮办”政务服务品牌,进一步提升政 -
 南阳市宛城区法院:抵制高额彩礼 推进移风易俗 咱们南阳的彩礼高不高?彩礼金给多少才合适?7月31日,南阳市宛城区人
南阳市宛城区法院:抵制高额彩礼 推进移风易俗 咱们南阳的彩礼高不高?彩礼金给多少才合适?7月31日,南阳市宛城区人 -
 全球新动态:中信保诚人寿着力打造新时代卓越保险企业家 中信保诚人寿着力打造卓越保险企业家,开启高质量发展新篇章在利率
全球新动态:中信保诚人寿着力打造新时代卓越保险企业家 中信保诚人寿着力打造卓越保险企业家,开启高质量发展新篇章在利率 -
 大童保险服务“童享荟”全面升级,全方位提升客户的健康管理体验 8月1日,大童保险服务的会员权益体系“童享荟”全面升级,从原有的V0-V
大童保险服务“童享荟”全面升级,全方位提升客户的健康管理体验 8月1日,大童保险服务的会员权益体系“童享荟”全面升级,从原有的V0-V -
 “八一”慰问子弟兵 共叙军民鱼水情——方城法院走访慰问县武装部官兵 为发扬拥军优属良好传统,巩固军政军民关系,8月1日,方城县人民法院党
“八一”慰问子弟兵 共叙军民鱼水情——方城法院走访慰问县武装部官兵 为发扬拥军优属良好传统,巩固军政军民关系,8月1日,方城县人民法院党 -
 每日焦点!2024北京理工大学深圳研究院2+2留学项目招生简章 2024北京理工大学深圳研究院2+2留学项目招生简章。报名材料:(1)报名申
每日焦点!2024北京理工大学深圳研究院2+2留学项目招生简章 2024北京理工大学深圳研究院2+2留学项目招生简章。报名材料:(1)报名申 -
 盛夏普探新征程——罗山四普队员奋战普查一线纪实_天天时快讯 近日,罗山县“四普办”普查队员在完成地下文物数据调查后,耐着高温,
盛夏普探新征程——罗山四普队员奋战普查一线纪实_天天时快讯 近日,罗山县“四普办”普查队员在完成地下文物数据调查后,耐着高温,
热门资讯
- 罗山县行政审批和政务信息管理局多举措做好安全生产管理工作 近年来,罗山县行政审批和政务信息...
-
 现代汽车2024年第二季度经营业绩再创新高 - 现代汽车2024年第二季度销售额...
现代汽车2024年第二季度经营业绩再创新高 - 现代汽车2024年第二季度销售额... -
 中韩合作新篇章:韩国apM集团前往福建考察,推动数字化转型与合作 7月23日至27日,韩国apM集团受君昇...
中韩合作新篇章:韩国apM集团前往福建考察,推动数字化转型与合作 7月23日至27日,韩国apM集团受君昇... -
 宇合光年×宁诺投资丨XBOX家庭运动中心:颠覆性的潮流运动新场景 由宁诺投资联合宇合光年设计打造的...
宇合光年×宁诺投资丨XBOX家庭运动中心:颠覆性的潮流运动新场景 由宁诺投资联合宇合光年设计打造的...
观察
图片新闻
-
 国家工作人员指定请托人购买第三人销售的产品,应如何认定? 实践中,有一种新的腐败表现形式,...
国家工作人员指定请托人购买第三人销售的产品,应如何认定? 实践中,有一种新的腐败表现形式,... -
 动态:2027年我国将初步建成30个左右国家邮政快递枢纽 近日,国家邮政局联合工业和信息化...
动态:2027年我国将初步建成30个左右国家邮政快递枢纽 近日,国家邮政局联合工业和信息化... -
 香港财政司司长陈茂波:香港整体发展氛围更为活跃 人民网香港7月28日电 (记者陈然...
香港财政司司长陈茂波:香港整体发展氛围更为活跃 人民网香港7月28日电 (记者陈然... -
 环球快报:公募自购固收产品“生意经”:久期相对较短 看重票息收益 今年以来,债市持续走牛。公募机构...
环球快报:公募自购固收产品“生意经”:久期相对较短 看重票息收益 今年以来,债市持续走牛。公募机构...
精彩新闻
- 罗山县举行漯河(国家级)知识产权快速维权中心罗山工作站揭牌仪式 7月24日上午,漯河(国家级)知识...
-
 羊山新区龙飞山街道办事处开展防汛应急演练|环球看热讯 根据“全市安全日”活动整体安排部...
羊山新区龙飞山街道办事处开展防汛应急演练|环球看热讯 根据“全市安全日”活动整体安排部... -
 云南2024年上半年GDP同比增3.5% 鲜切花咖啡出口全国第一 中新网昆明8月1日电 (罗婕)上半年...
云南2024年上半年GDP同比增3.5% 鲜切花咖啡出口全国第一 中新网昆明8月1日电 (罗婕)上半年... -
 贝莱德基金多项投研人事调整,排兵布将之后如何发力产品布局? 8月2日讯(记者闫军)外商独资公募正...
贝莱德基金多项投研人事调整,排兵布将之后如何发力产品布局? 8月2日讯(记者闫军)外商独资公募正... -
 内乡县城管:“八一”军魂永不褪色 城管“铁军”再铸辉煌 为庆祝中国人民解放军建军97周年,...
内乡县城管:“八一”军魂永不褪色 城管“铁军”再铸辉煌 为庆祝中国人民解放军建军97周年,... -
 拼多多向中国农大捐赠1亿元成立研究基金后,成果接连登上《细胞》《自然》等国际顶... 据中国农业大学官网消息,近期, ...
拼多多向中国农大捐赠1亿元成立研究基金后,成果接连登上《细胞》《自然》等国际顶... 据中国农业大学官网消息,近期, ... -
 雷军带苏炳添体验SU7霞光紫:队友委托催车 8月2日上午消息,小米创始人雷军在...
雷军带苏炳添体验SU7霞光紫:队友委托催车 8月2日上午消息,小米创始人雷军在... -
 报告:亚洲城市在国际交往中心城市中活跃度稳步崛起-时快讯 中新网北京8月1日电(宫宏宇)近日发...
报告:亚洲城市在国际交往中心城市中活跃度稳步崛起-时快讯 中新网北京8月1日电(宫宏宇)近日发... -
 天天看点:(经济观察)中央政治局会议提到的“瞪羚企业”是什么? 中新社北京8月1日电 (记者 陈康...
天天看点:(经济观察)中央政治局会议提到的“瞪羚企业”是什么? 中新社北京8月1日电 (记者 陈康... -
 8月2日人民币对美元中间价报7.1376元 下调53个基点-世界报道 中新网8月2日电 据中国外汇交易中...
8月2日人民币对美元中间价报7.1376元 下调53个基点-世界报道 中新网8月2日电 据中国外汇交易中... - 现代汽车2024年第二季度经营业绩再创新高 - 现代汽车2024年第二季度销售额...
-
 油脂油料板块多数走跌 豆一主力涨逾1% 当前时讯 截至目前,豆一主力上涨1 54%,报...
油脂油料板块多数走跌 豆一主力涨逾1% 当前时讯 截至目前,豆一主力上涨1 54%,报... - 商务部:支持地方自主提升以旧换新能力 指导地方及时完善配套措施-全球焦点 中新网8月2日电 国新办2日举行推...
- 焦点快播:广州楼市再出新政:可提取公积金作购房首付款 为落实广州市人民政府办公厅《关于...
- 中韩合作新篇章:韩国apM集团前往福建考察,推动数字化转型与合作 7月23日至27日,韩国apM集团受君昇...
-
 邓州市杏山旅游管理区召开慰问退役军人座谈会 每日快播 8月1日,值此八一建军节之际,杏山...
邓州市杏山旅游管理区召开慰问退役军人座谈会 每日快播 8月1日,值此八一建军节之际,杏山... -
 邓州市民政局殡葬服务中心:开展灾后病毒消杀 优化服务促安全 眼下,为预防洪涝过后灾害,邓州市...
邓州市民政局殡葬服务中心:开展灾后病毒消杀 优化服务促安全 眼下,为预防洪涝过后灾害,邓州市... -
 环球实时:北京理工大学深圳研究院国际本科2+2申请条件 北京理工大学深圳研究院国际本科2+...
环球实时:北京理工大学深圳研究院国际本科2+2申请条件 北京理工大学深圳研究院国际本科2+... -
 当前快看:中消协发布上半年消费维权舆情热点报告 多领域存在消费堵点亟待打通 今天,中国消费者协会发布2024年上...
当前快看:中消协发布上半年消费维权舆情热点报告 多领域存在消费堵点亟待打通 今天,中国消费者协会发布2024年上... - 泰康人寿健康管理服务半年超150万人次 近期,泰康人寿发布健康管理服务半...
-
 山东安丘农商行主体评级被下调至A+级 根据相关规定,对于有债券存续的商...
山东安丘农商行主体评级被下调至A+级 根据相关规定,对于有债券存续的商... -
 商业银行新增二永债规模破万亿,年内唯二不赎回案例均来自农商行|每日速看 昨日,河北宁晋农村商业银行股份有...
商业银行新增二永债规模破万亿,年内唯二不赎回案例均来自农商行|每日速看 昨日,河北宁晋农村商业银行股份有... -
 全球观热点:山东安丘农商行主体评级被下调至A+级 根据相关规定,对于有债券存续的商...
全球观热点:山东安丘农商行主体评级被下调至A+级 根据相关规定,对于有债券存续的商... -
 银行理财规模景气度延续,配置策略或将分化:2024年半年报分析 2024年上半年理财市场扩张态势积极...
银行理财规模景气度延续,配置策略或将分化:2024年半年报分析 2024年上半年理财市场扩张态势积极... -
 银行理财规模景气度延续,配置策略或将分化:2024年半年报分析_热文 2024年上半年理财市场扩张态势积极...
银行理财规模景气度延续,配置策略或将分化:2024年半年报分析_热文 2024年上半年理财市场扩张态势积极... -
 多家银行火速跟进,“降息”! 随着国有大行及股份制银行相继下调...
多家银行火速跟进,“降息”! 随着国有大行及股份制银行相继下调... -
 天天速递!以进一步全面深化改革为强劲动力 推动经济高质量发展 深化经济体制改革是进一步全面深化...
天天速递!以进一步全面深化改革为强劲动力 推动经济高质量发展 深化经济体制改革是进一步全面深化... -
 民营经济促进法正在制定中 着眼解决经营主体市场准入等问题 8月1日,国新办举行的“推动高质量...
民营经济促进法正在制定中 着眼解决经营主体市场准入等问题 8月1日,国新办举行的“推动高质量... -
 环球快看:千亿新增贷款投向哪里 ——解读促进上半年经济稳定增长的主要金融数据 今年上半年,我市金融行业积极贯彻...
环球快看:千亿新增贷款投向哪里 ——解读促进上半年经济稳定增长的主要金融数据 今年上半年,我市金融行业积极贯彻... -
 天天新资讯:将发布新版市场准入负面清单 国家发展改革委负责人回应经济发展热点问题 如何看待下半年经济走势?怎样更好...
天天新资讯:将发布新版市场准入负面清单 国家发展改革委负责人回应经济发展热点问题 如何看待下半年经济走势?怎样更好... -
 A股分红派息转增一览:5股今日股权登记 每经AI快讯,数据显示,根据上市公...
A股分红派息转增一览:5股今日股权登记 每经AI快讯,数据显示,根据上市公... -
 操盘必读:行业巨头研发闪存堆叠新技术,AI需求持续旺盛;道指跌近500点,英特尔盘... (一)重要市场新闻1、美股高开低...
操盘必读:行业巨头研发闪存堆叠新技术,AI需求持续旺盛;道指跌近500点,英特尔盘... (一)重要市场新闻1、美股高开低... -
 A股分红派息转增一览:5股今日股权登记-全球观点 每经AI快讯,数据显示,根据上市公...
A股分红派息转增一览:5股今日股权登记-全球观点 每经AI快讯,数据显示,根据上市公... -
 日本股市崩了!日经225指数、东证指数跌幅均扩大至超4% 大幅低开后,日经225指数、东证指...
日本股市崩了!日经225指数、东证指数跌幅均扩大至超4% 大幅低开后,日经225指数、东证指... -
 全球芯片行业遭遇重创 !英特尔盘后一度跌超20%,财报引发市场震荡 近期,全球芯片行业遭遇重创,美股...
全球芯片行业遭遇重创 !英特尔盘后一度跌超20%,财报引发市场震荡 近期,全球芯片行业遭遇重创,美股... -
 A股股票回购一览:318家公司披露回购进展 每经AI快讯,数据显示,8月2日,共...
A股股票回购一览:318家公司披露回购进展 每经AI快讯,数据显示,8月2日,共... -
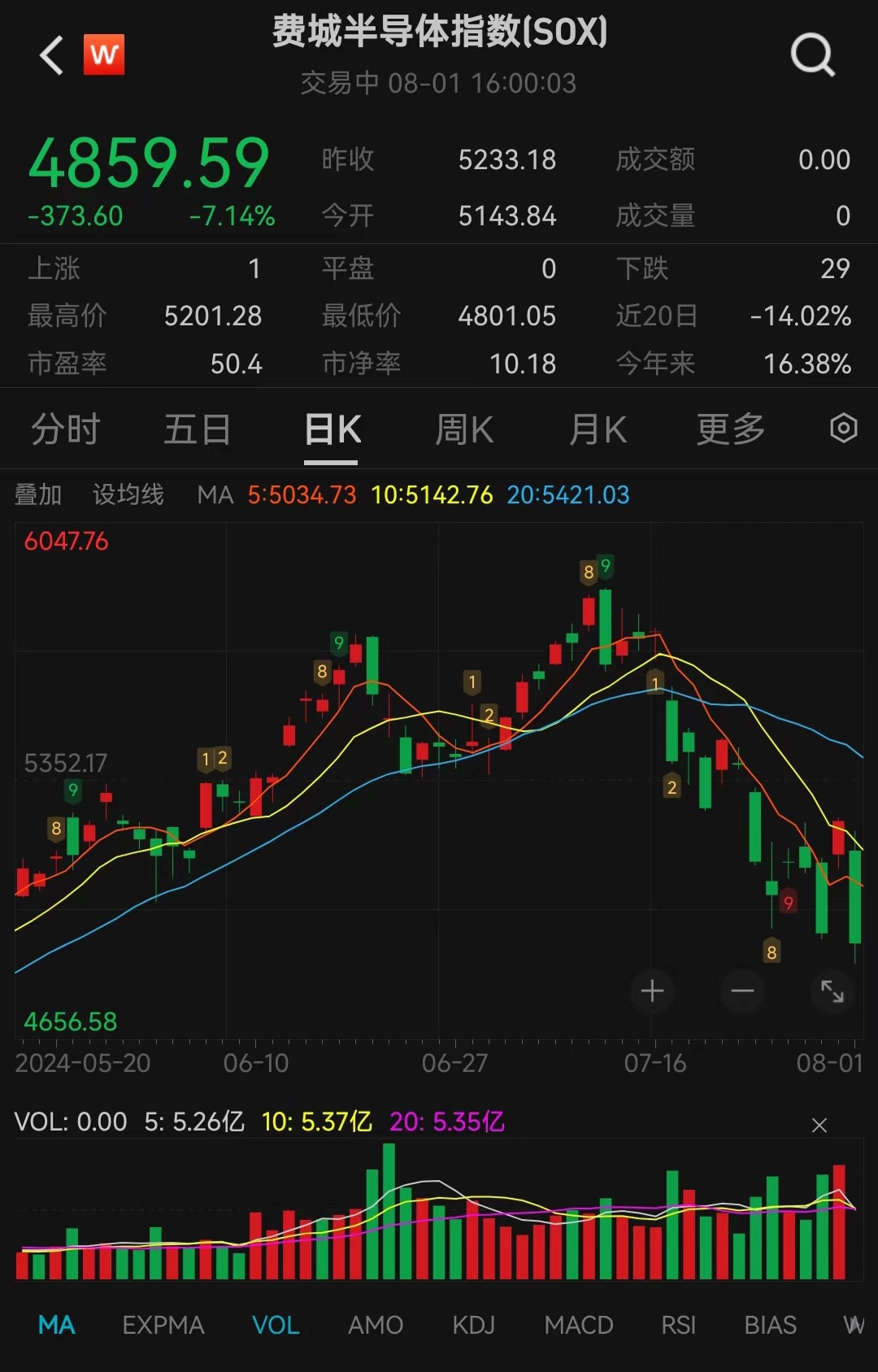 聚焦:全球芯片行业遭遇重创 !英特尔盘后一度跌超20%,财报引发市场震荡 近期,全球芯片行业遭遇重创,美股...
聚焦:全球芯片行业遭遇重创 !英特尔盘后一度跌超20%,财报引发市场震荡 近期,全球芯片行业遭遇重创,美股... -
 世界关注:邓州市开展“司法联谊”---“经警讲法”活动 为持续优化营商环境,进一步增强企...
世界关注:邓州市开展“司法联谊”---“经警讲法”活动 为持续优化营商环境,进一步增强企... -
 全球短讯!西平县应急管理局对辖区人员劳动密集型、“厂中厂”企业进行安全生产... 根据近期高温和极端天气火灾防控形...
全球短讯!西平县应急管理局对辖区人员劳动密集型、“厂中厂”企业进行安全生产... 根据近期高温和极端天气火灾防控形... -
 西平县应急管理局收听收看全市洪涝灾害灾情核查评估工作视频培训会|天天微头条 7月31日,西平县应急管理局副局长...
西平县应急管理局收听收看全市洪涝灾害灾情核查评估工作视频培训会|天天微头条 7月31日,西平县应急管理局副局长... -
 百事通!驻马店市驿城区诸市镇:文化惠民暖人心 敬老院里幸福多 戏曲声声,暖意融融。为弘扬尊老、...
百事通!驻马店市驿城区诸市镇:文化惠民暖人心 敬老院里幸福多 戏曲声声,暖意融融。为弘扬尊老、... - 宇合光年×宁诺投资丨XBOX家庭运动中心:颠覆性的潮流运动新场景 由宁诺投资联合宇合光年设计打造的...
-
 前沿资讯!驻马店市驿城区雪松街道纱厂社区党支部举办庆八一活动 在八一建军节来临之际,为热烈庆祝...
前沿资讯!驻马店市驿城区雪松街道纱厂社区党支部举办庆八一活动 在八一建军节来临之际,为热烈庆祝... -
 新野县法院:开展“法律明白人”培训 绘制基层社会治理新“枫”景|焦点速讯 为进一步推进诉源治理走深走实,提...
新野县法院:开展“法律明白人”培训 绘制基层社会治理新“枫”景|焦点速讯 为进一步推进诉源治理走深走实,提... -
 【环球新要闻】邓州市法院:“走出去”共叙鱼水情 开启拥军新篇章 7月31日上午,八一建军节即将来临...
【环球新要闻】邓州市法院:“走出去”共叙鱼水情 开启拥军新篇章 7月31日上午,八一建军节即将来临... -
 邓州市腰店镇卫生院:积极开展防疫培训 优化居民健康环境 天天新视野 眼下,邓州市腰店镇卫生院将人民的...
邓州市腰店镇卫生院:积极开展防疫培训 优化居民健康环境 天天新视野 眼下,邓州市腰店镇卫生院将人民的... -
 2024HS×CCFW中国国际时尚周・HS品牌色彩首秀圆满落幕! 看见世界的缤纷领略色彩的魅力7月2...
2024HS×CCFW中国国际时尚周・HS品牌色彩首秀圆满落幕! 看见世界的缤纷领略色彩的魅力7月2... -
 五粮液:传承红色基因 爱国拥军花开“十里酒城” 8月1日,是中国人民解放军建军97周...
五粮液:传承红色基因 爱国拥军花开“十里酒城” 8月1日,是中国人民解放军建军97周... -
 Allegro Smart!免运费计划:从亚洲发货,助力中国卖家高效拓展中东欧市场 跨境电商的全球化趋势愈发显著,各...
Allegro Smart!免运费计划:从亚洲发货,助力中国卖家高效拓展中东欧市场 跨境电商的全球化趋势愈发显著,各... -
 当前信息:驻马店市驿城区朱古洞乡:资源普查聚合力 文旅建设提效力 为深入贯彻落实关于开展旅游资源普...
当前信息:驻马店市驿城区朱古洞乡:资源普查聚合力 文旅建设提效力 为深入贯彻落实关于开展旅游资源普...